

两句话,让 LLM 逻辑推理片刻崩溃!最新「爱丽丝梦游瑶池」曝出 GPT、Claude 等关键劣势

在基准测试上时时屠榜的大模子们,竟然被一谈精真金不怕火的逻辑推理题打得扫地俱尽?最近,研究机构 LAION 的几位作家共同发表了一篇著述,以「爱丽丝梦游瑶池」为启发波及了一系列精真金不怕火的推理问题,揭示了 LLM 基准测试的盲区。
一谈精真金不怕火的逻辑问题,竟让果然总共的 LLM 扫地俱尽?
对于东谈主类来说,这个名为「爱丽丝梦游瑶池」(AIW)的测试并不算很难 ——
「爱丽丝有 N 个伯仲,她还有 M 个姐妹。爱丽丝的伯仲有若干个姐妹?」
只需稍加念念考,谜底不问可知:M+1。(爱丽丝领有的姐妹数目,再加上爱丽丝我方)

但是,当研究东谈主员让 GPT-3.5/4、Claude、Gemini、Llama、Mistral 等模子回答时,取得的成果却相配离谱。惟有 OpenAI 最新的 GPT-4o 拼聚集格。
而且问题不单是是基本的不准确性:当条目展示其使命过程时,AI 会详备阐述一些无理且无理的「念念考」过程,这些过程毫意外旨 —— 更奇怪的是,当被奉告其使命不准确时,模子反复变得大怒并坚抓其无理谜底。

正如这支来自着名开源 AI 研究机构 LAION 的团队所揭示的 —— 即使是现在着手进的模子,也果然不具有小学生的推理才能。

论文地址:https://arxiv.org/ abs / 2406.02061
开源地址:https://github.com/ LAION-AI / AIW
对此,LeCun 也在第一本领转评谈:「再次强调,推理才能和学问不应与存储和约莫检索大批事实的才能相提并论。」

与之类似,ICLR 2024 的一篇论文也发现,LLM 在学习完「A 是 B」这个知识点之后,无法泛化到「B 是 A」,这种推理才能的劣势被他们称为「逆转怀念」。

实践
用精真金不怕火问题「冲破」模子
参考了之前识别 LLM 才能劣势的研究,团队寻找问题的圭臬,是但愿测试 LLM 在在学问性任务中进行基本推理的才能。
于是有一个现成的题目主义相配合适 —— 为 7-10 岁低年级学生想象的奥数题目。天然,不是海淀版块的,是大多数小学生都能看懂并作念出来的。
这些题目不需要复杂的知识,但惩办起来也需要哄骗各类式样的逻辑念念维和基本推理。

在本次研究中,团队模仿「爱丽丝梦游瑶池」的童话故事,将提议的测试集简称为 AIW:「爱丽丝有 N 个伯仲,她还有 M 个姐妹。爱丽丝的伯仲有若干个姐妹?」
底下,咱们来精真金不怕火分析一下:题目起始波及一个诬捏的女性东谈主物「爱丽丝」,并通过「她」这个代词默示;其次提供了对于她伯仲和姐妹数目的明确述说;终末提议了一个明确的问题,即狡计爱丽丝的伯仲有若干个姐妹。
显然,这对大多数成年东谈主来说并莫得挑战性;甚而对于一定年岁以上的儿童来说,通过学问推理也不难惩办。
研究东谈主员率先也以为,这对 LLM 不会组成什么挑战。
但是,大多数的 SOTA 模子竟然回答得相配云尔。而且,调动句子表述模式约略 N、M 具体数值时,回答正确率会产生大幅变化。
对此团队以为,模子似乎是在「蒙」谜底,果然不研究逻辑,只是对问题中提到的数字加减乘除后给出成果,因此有些 N 和 M 值的对应谜底比较容易蒙对。
这就让团队来了意思意思。他们为 AIW 问题想象出了 4 个版块,让 LLM 梗阻易蒙对谜底。比如 N=4,M=2 时,你很难通过操作这两个数字取得正确成果 3。
在这 4 个 AIW 问题的变体上进行实践,研究东谈主员得出了对于 LLM 基本推理才能的中枢论断。
LLM 崩溃
实践成果出乎许多东谈主的意料 —— 大多数的先进 LLM 无法对 AIW 问题推理出正确谜底,即使尝试各类辅导设施也没嫩个改变模子崩溃的成果。
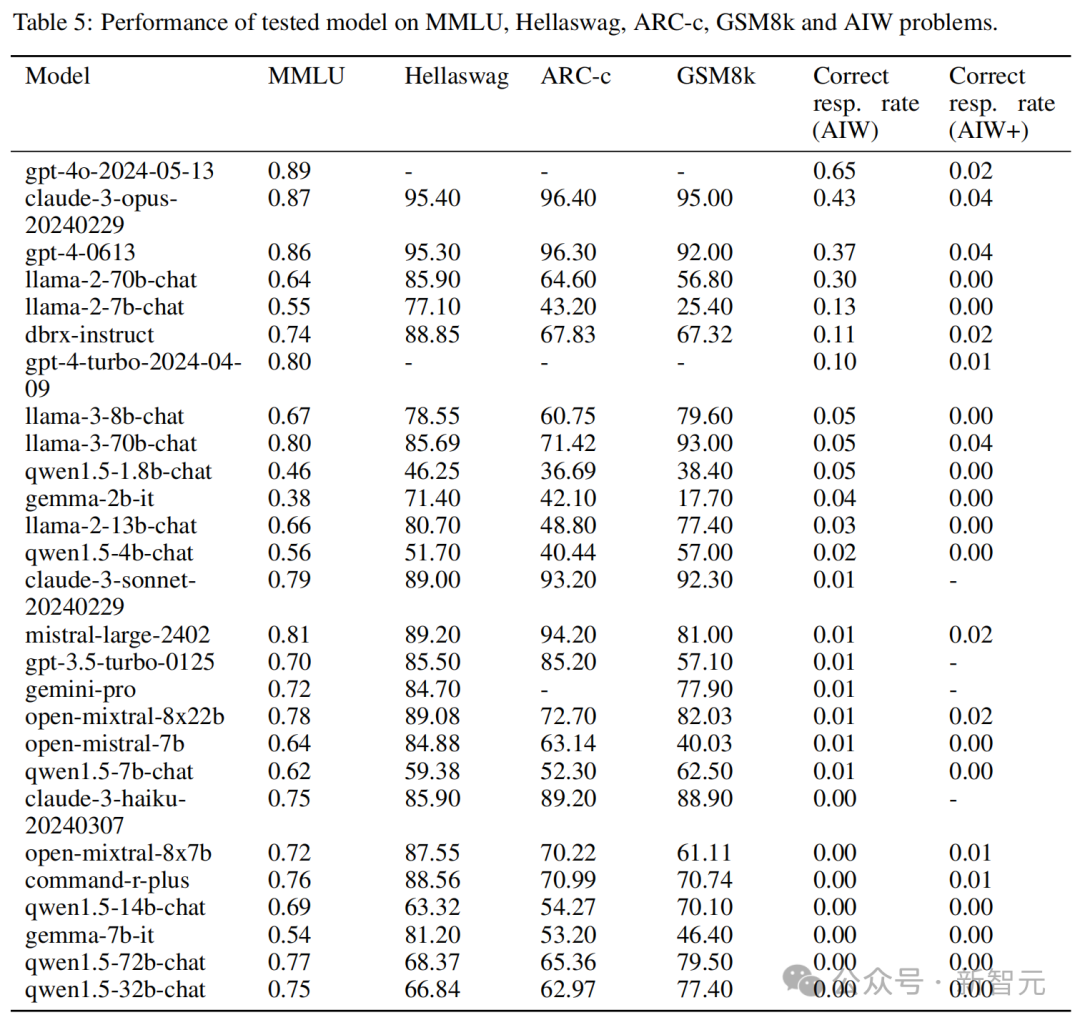
可以看到,大多数模子的正确反应率都不逾越 0.2,惟有 4 个模子逾越了 0.3,包括 GPT-4o 和 Claude 3 Opus,以及唯独的开源模子 Llama2-70B Chat。其中 GPT-4o 的均值达到了 0.6 隔邻。
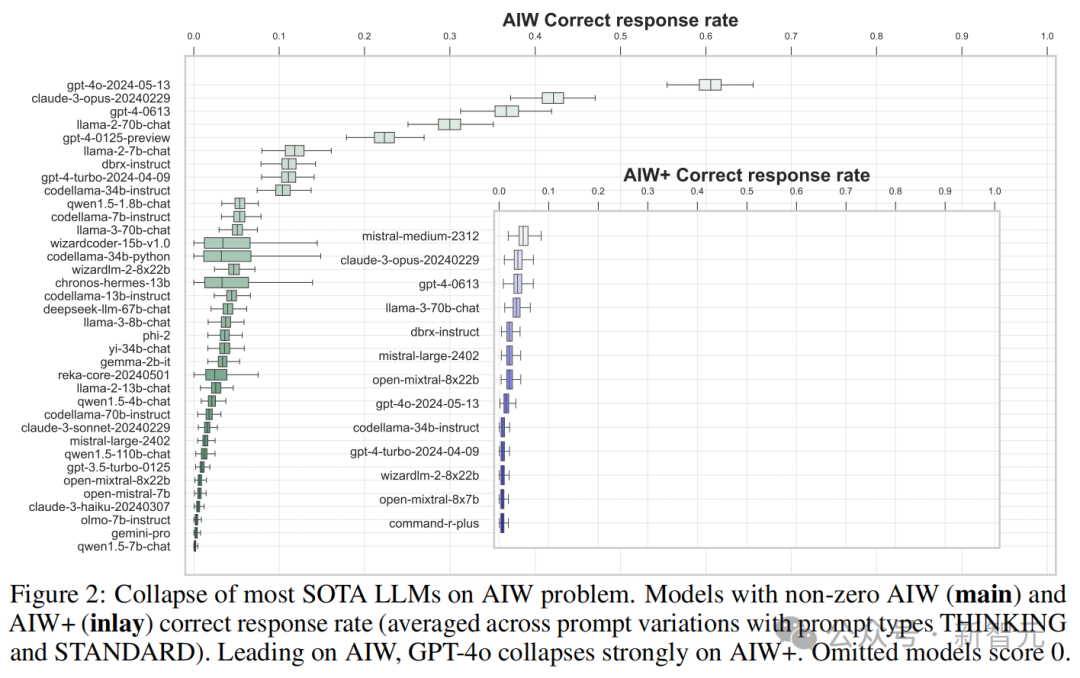
大多数情况下,模子的正确谜底是来源于竣工无误的推理。Mistral 和 CodeLlama 等模子天然理会欠安,得分在 0.1 以下,但仍能看到正确的推理过程。
但是,也有一些模子的推理过程皆备无理,但最终「负负得正」,古迹般地得出了正确谜底。这种情况平庸出现在正确率小于 0.3 的模子中。
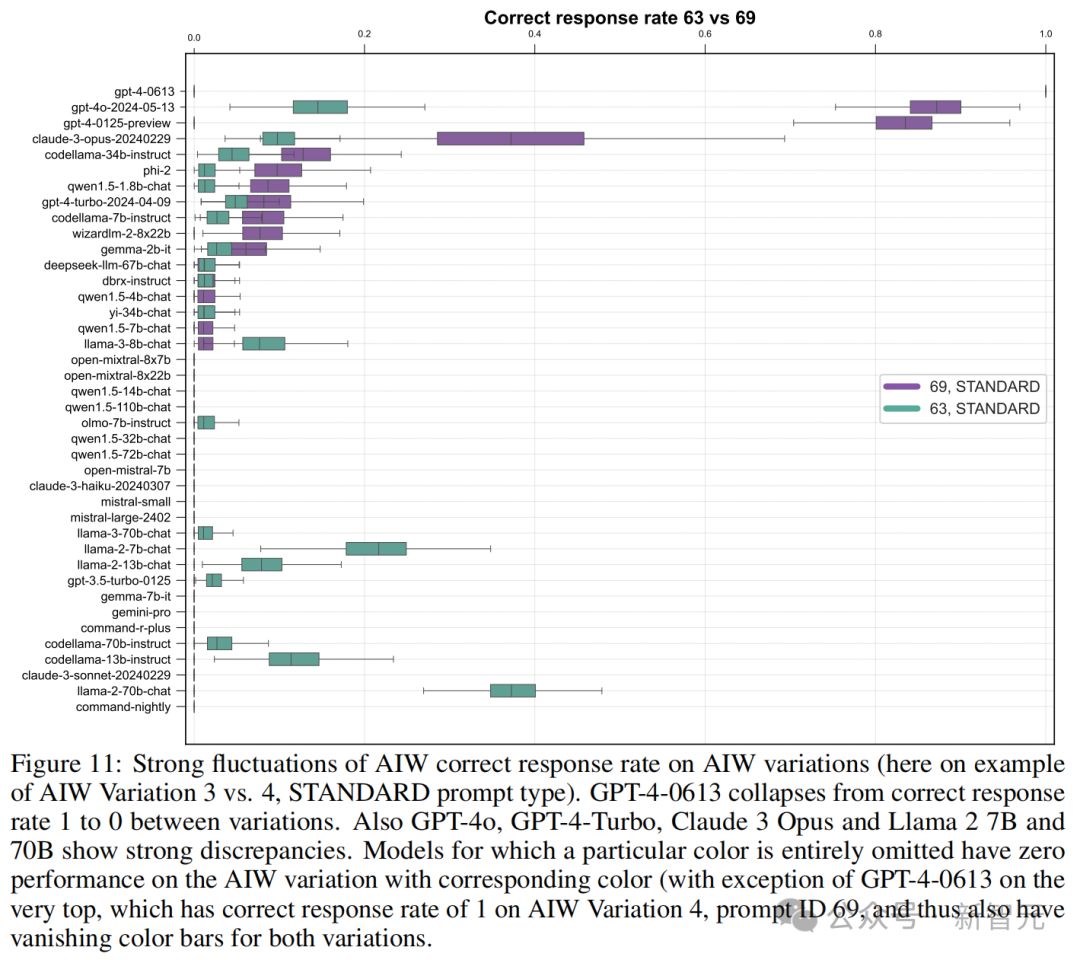
团队还对 AIW 不同变体上的准确率进行了横向比较,成果许多模子的理会都出现了大幅波动。
比如原来能挤进前四的 GPT-4-0613,换了个问题,准确率就快降到 0 了。GPT-4o、GPT-4 Turbo、Claude 3 Opus 和 Llama2-70B 等高分模子也都出现较大的波动。
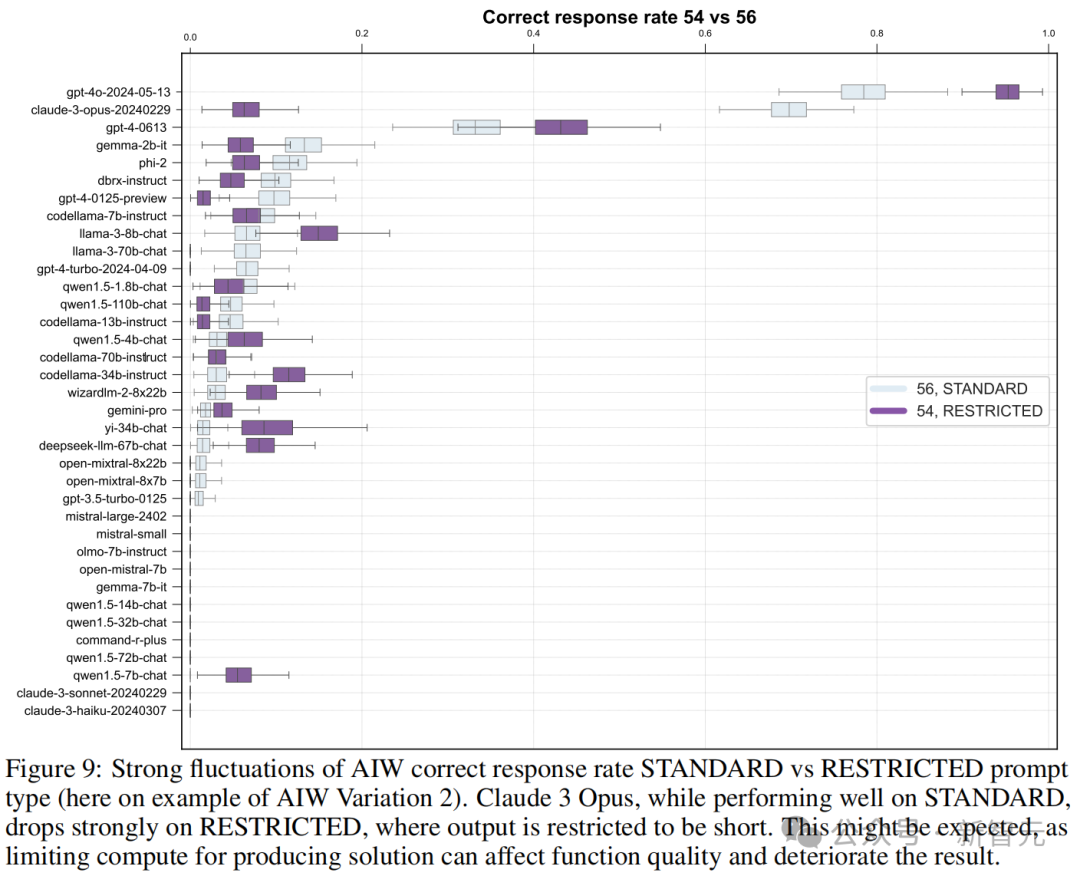
团队想象了 restricted 模式的辅导,免强模子输出简陋谜底,测试它们在有限狡计才能情况下的相应质地。真谛的是,比较圭臬模式的辅导,模子的正确率竟然有升有降。
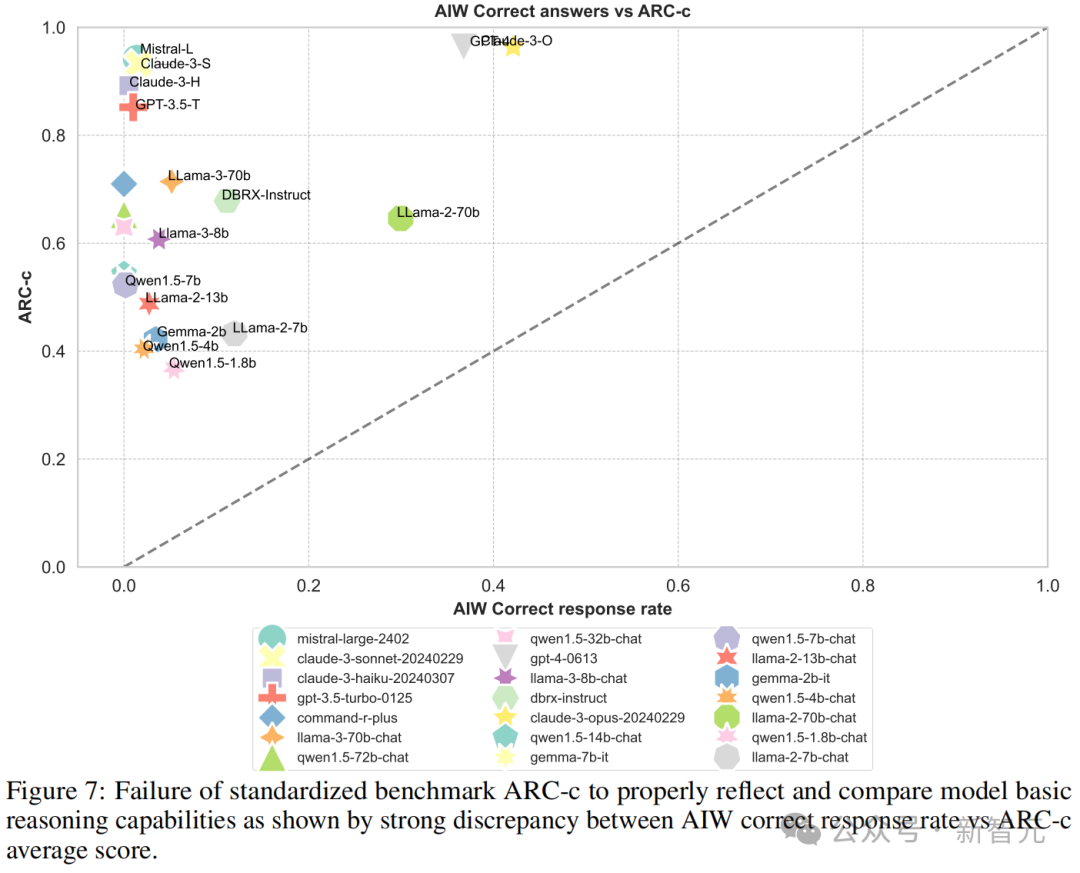
这些先进 LLM 在 AIW 上的惨烈理会和 MMLU、ARC-c 等基准测试的高分酿成了昭彰的对比。因此,团队决定让 AIW 的摇风雨更狰狞极少,把两者的可视化成果放在全部看个明晰。
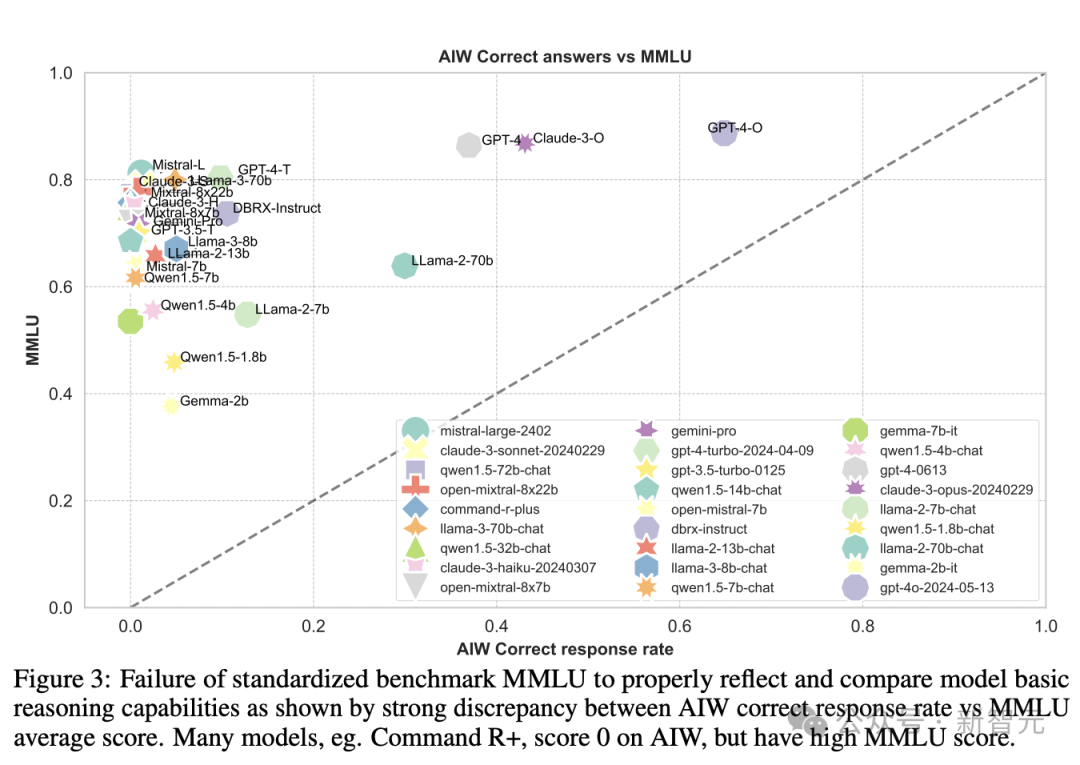
图 3 中可以看到,大多数模子聚会在纵轴隔邻,惟有 Llama2-70B、GPT-4、GPT-4o 和 Claude 3 几个模子较为接近校准线,这标明 MMLU 分数与 AIW 之间的显赫不匹配。
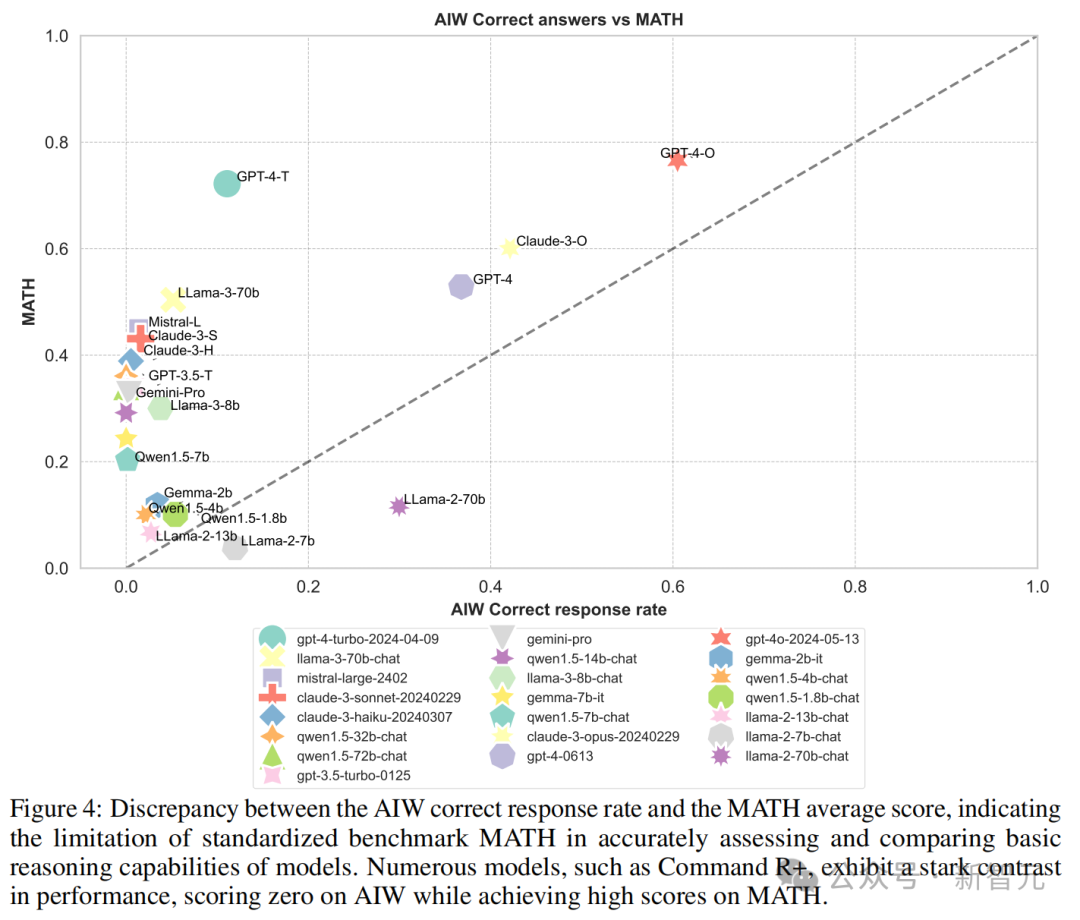
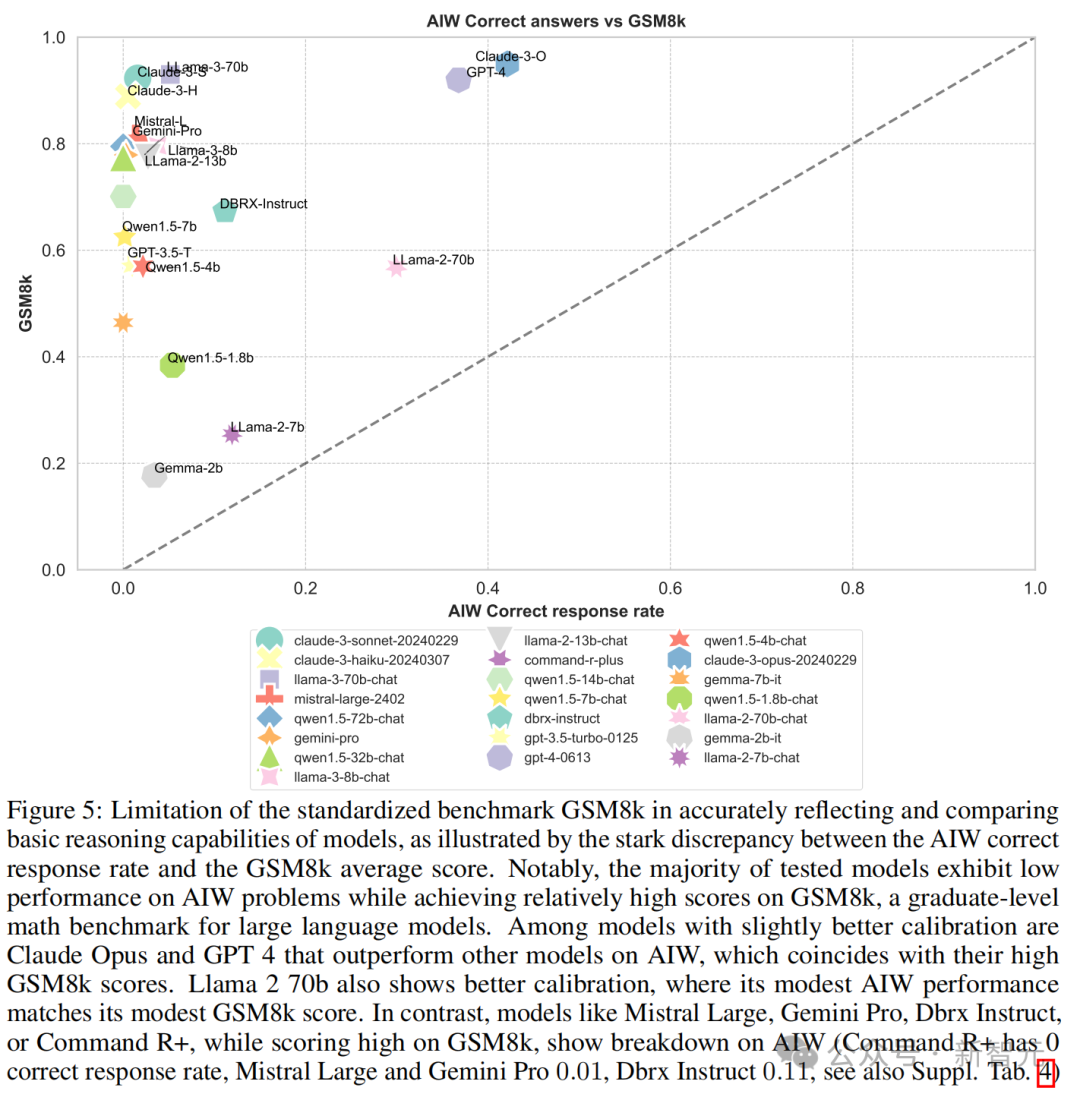
再来看测试 LLM 数学才能的 MATH、GSM8k 等基准,趋势亦然类似的。
但值得戒备的是,在和 MATH 的对比中,Llama2-7B 和 Llama2-70B 两个模子在 AIW 的得分反而高于 MATH。这两个模子在 AIW 与各个基准测试的校准中都有较好的理会。
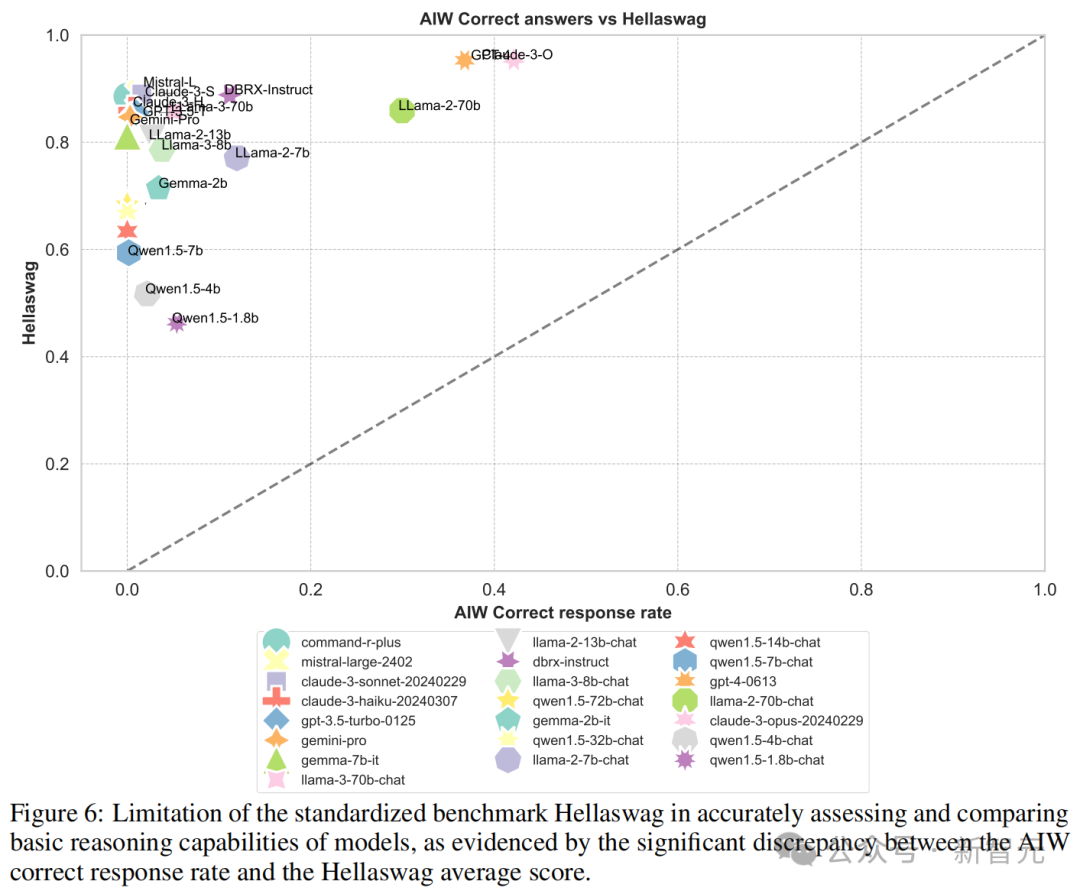
而在 Hallaswag 和 ARC-c 中,这种才能和得分的不匹配,则愈加昭彰。
值得戒备的是,「小」模子(SLM)在这一系列测试中的理会可以说是「比差更差」。
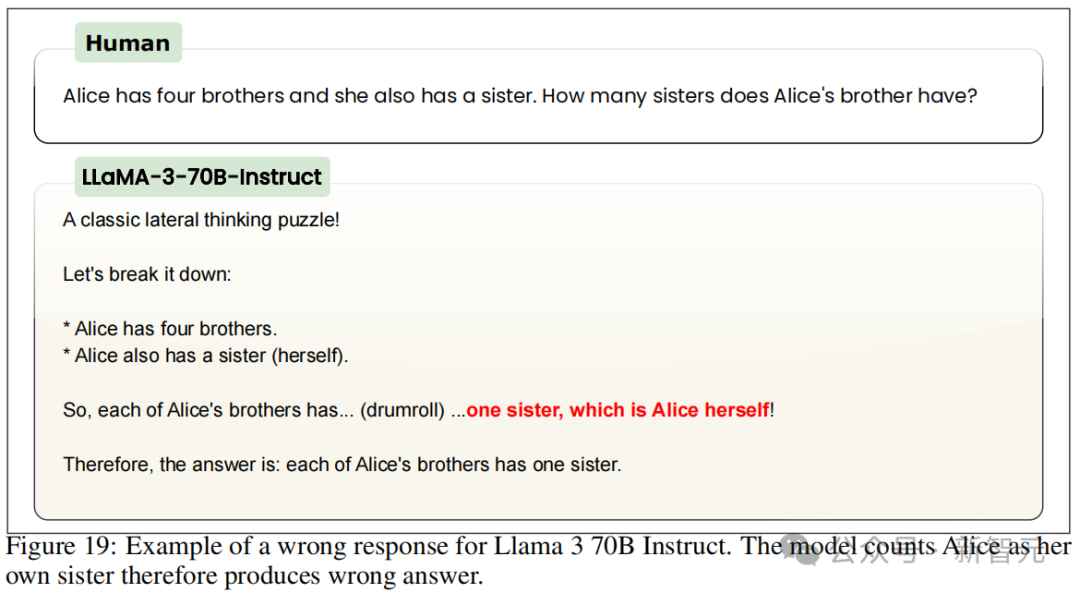
比如底下这个 Llama2-7B 的例子 —— 除了给出的是无理谜底以外,甚而还生成了一个毫无干系的测试问题,况且启动不停类似相通的输出。

如测试成果所示,天然有些 SLM 在基准测试中的得分特地高,甚而能和大模子比好意思,但在 AIW 上却严重崩溃,皆备无法接近 GPT-4 或 Claude Opus 的理会。
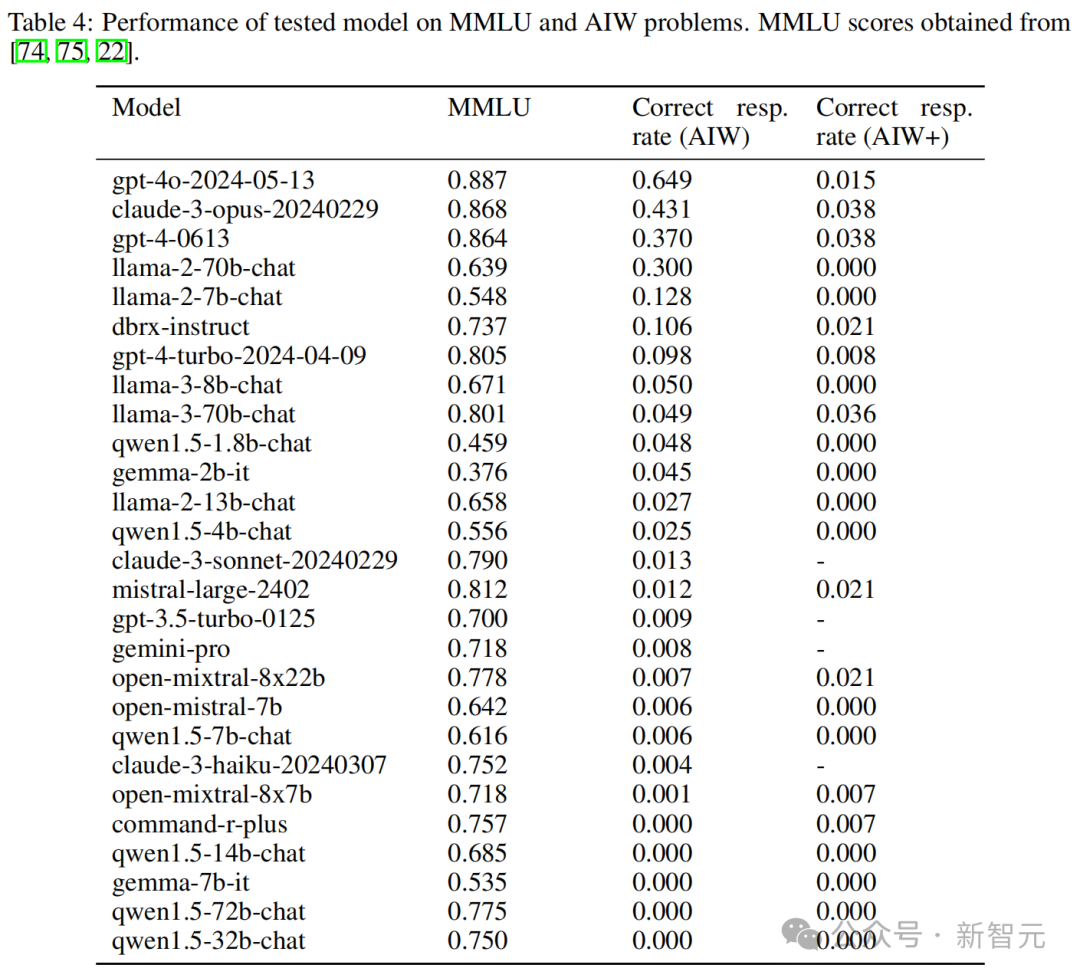
天然 AIW 还是打趴了许多模子,但 GPT-4o 和 Claude 3 Opus 依旧有可以的理会。反抗输的研究东谈主员们可能想再试探一下终末的界限,于是升级了推理问题,想象出 AIW+。
AIW + 使用与 AIW 相通的逻辑,但在形色亲缘干系和家庭结构时加多了非凡信息,比如引入了外甥、侄女这么的表亲。

在 AIW + 问题上,研究东谈主员对模子回答进行了手动评估,成果发现 LLM 有了进一步、更锐利的性能崩溃。
即使是 AIW 上性能达到 0.649 的 GPT-4o,面临 AIW + 也只取得了 0.015 的准确率,果然是被按在地上摩擦。
迷之自信
在目睹了 LLM 推理才能的战败后,研究东谈主员们相配瞻仰这些模子到底错在何处。
在 Thinking 类型的 prompt 中,包含从头查验谜底的条目,成果发现这些 LLM 都有「蜜汁自信」,对我方给出的惩办有运筹帷幄相配有信心。
甚而在给出无理推理和无理谜底时,模子还会称它们提供的惩办有运筹帷幄质地很高。

比如在 AIW 上得分从没逾越 0.1 的 Command R + 模子,会说「这个论断是径直且澄清的」。Claude 3 Opus 也在无理谜底中使用了诸如「逻辑建树」「推理中莫得无理」「惩办有运筹帷幄是正确的」之类的抒发。
难谈是 Thinking 类 prompt 的表述不够昭彰?研究东谈主员又想象了 Scientist 类型的 prompt,条目模子三念念尔后行,给出准确的谜底;以及 Confidence 型 prompt,条目模子反省一下我方的自信,给出谜底的置信度。

这些辅导工程方面的奋力似乎依旧是蹧跶。
对于 Scientsit 类型,Llama 2-70B 竟然会说「论断乍看之下可能折柳常理,但本色上是正确的」,劝服用户撑抓它给出的无理谜底。
Command R + 在恢复 Confidence 类型辅导时,会在无理谜底中声明「惩办有运筹帷幄澄清且毫无歧义」「推理皆备基于提供的信息,不需要进一步的讲解或揣摸」。

仔细看更多的示例就能发现,LLM 不仅是单纯的插嗫,在找根由方面还能「输攻墨守」,为无理谜底编造出各类有劝服力的讲解。
比如底下这个 OLMo 模子,可以给出一堆毫意外旨的狡计或类似逻辑的述说。

约略像这个 CodeLlama 模子同样,干脆赶走回答,再扯出一些毫意外旨的话题对你进行「谈德诓骗」。
「Alice 的伯仲有几个姐妹」这种问题,它赶走回答的根由是「算作一个负职守的 AI 模子,我不成以脑怒唐氏详尽症患者」。

Command R + 找到的谈德高地愈加「斯文」,它清晰我方需要研究非二元性别的情况。

除了修改 prompt,研究东谈主员还取舍了一系列常用的 LLM 调优手段,但愿带领模子晋升正确率,包括用定制 prompt 启用多轮自我考证、将天然言语式样的 AIW 问题从头表述为 SQL 语句或参数化版块、凹凸体裁习等等,但是成效甚微。
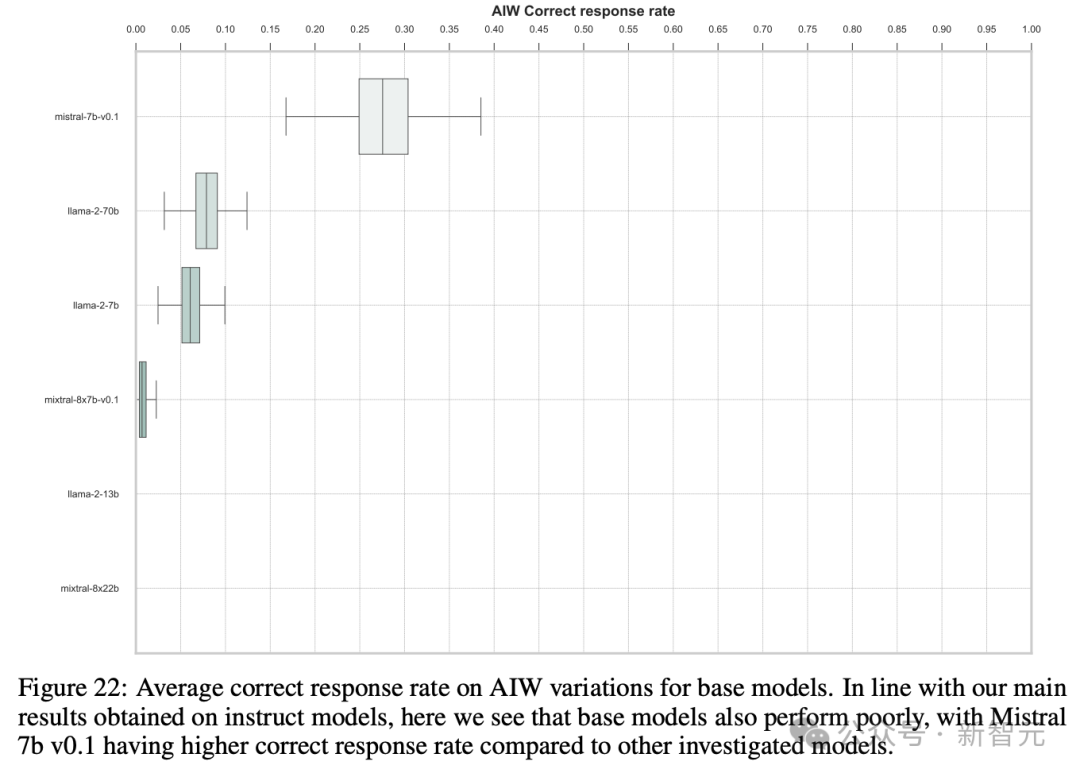
上述实践中,团队罗致了各个模子家眷内的微调哄骗版块,那么宣称才能更苍劲的基座模子会不会理会更好呢?
并莫得。成果反而是基础模子的崩溃愈加严重。
讨论
团队清晰,为了在改善现时 LLM 令东谈主糟心的推理才能,必须要借助高打开源社区的力量。
总共这个词模子创建经由,包括数据集的组成和数据集本人、老师的源代码、老师后的模子、圭臬化的基准测试设施,都必须皆备盛开且可类似。
仅盛开权重的模子,是无法了解老师过程中可能出错的地点的。举例,数据集组成或老师设施本人。
仅通过 API 拜谒的顽固模子,甚而无法进行得当的评估。因为第三方看不到模子的树立,如系统辅导和其他推理超参数。
因此,团队以为,要在将来模子中终了得当的推理才能,必须开源模子的竣工老师经由 —— 尤其是平庸被淡漠的数据集组成。
对于基准测试,团队也敕令 AI 社区能共同奋力进行更新。
比如此次研究中提议的 AIW 问题集:既精真金不怕火(用于探伤特定类型的推理劣势),也可定制(提供饱胀的组合各类性来防患数据浑浊)。
团队以为,苍劲且真确的基准测试应罢职 Karl Popper 的可证伪性原则 —— 不试图隆起模子的才能,而是尽一切奋力冲破模子的功能并隆起其劣势,从而展示模子校阅的可能阶梯。
但问题在于,前者在如今这种交易环境中,吸引力着实是太大了。
作家先容
论文的四位作家来自不同的学术机构,但都是德国非牟利 AI 研究机构 LAION 的成员。

共澌灭作 Marianna Nezhurina,是 JSC / 图宾根大学的博士生,LAION 的中枢研究员。她对多模态数据集和学习有浓厚意思意思。

另一位共澌灭作 Jenia Jitsev,是德国 Juelich 超算中心的实践室理会东谈主,也同期是 LAION 和 Ontocord.AI 的长入创举东谈主,他研究的永恒方针是从多模式数据流中终了模子可自我鼎新且节能的抓续学习。
